
SREがカバー株式会社に入社して3ヶ月でおこなったこと

こんやっぴー👾
カバー株式会社 技術開発本部のSです。カバー株式会社では組織横断的にSRE(Site Reliability Engineering)やサーバーサイドのエンジニアをしています。
2023年5月に入社し3ヶ月ほどホロプラスのパフォーマンスチューニングや開発環境の整備をしてきましたので、今回はそちらについてご説明します。
ホロプラスとは?
ホロプラスは「推しをもっと好きになる!」がコンセプトの、ホロライブプロダクション公式アプリです。先日8月29日に正式リリースされました。主に、以下の二つの体験を提供します。
ホロライブプロダクションの最新情報が公式アプリならではの機能で手軽に逃さずチェックできる
共感でつながるファンコミュニティで投稿やいいねを通じたコミュニケーションが楽しめる

ホロプラスのシステム構成
ホロプラスは図のようなシンプルな構成でGo言語のAPIがECS Fargateで動いており、DBにはAurora Serverless V2を使用しています。

ホロプラスの課題
ホロプラスのアプリやその開発には2つの大きな課題がありました。
パフォーマンス
ホロプラスは3/18から8/9までCBT(Closed Beta Test)をおこない、事前登録いただいた約1.1万人のみなさまに使っていただきました。
そのCBTでの大きな課題の一つがシステムのパフォーマンスです。CBTでユーザ数を絞っているもののパフォーマンスが低く、この時のAPIのレイテンシは99th percentileで4秒程度ととてつもない値を示していました。これに対してコストをかけたインフラの増強や機能制限によってなんとかしのいでいる状況でした。そのためインフラの料金が高額になっていました。
開発環境
当時はホロプラスのチームにSREがおらず、開発環境に課題を抱えていました。
CI/CDが十分に整備されておらずデプロイが手動で行われている
APIのリリースのために常にメンテナンスを入れる必要がある
監視の自動化が足りておらずエンジニアの監視コストが高い
ソフトウェアテストが動いていない
分散負荷試験環境がない
パフォーマンスの改善
パフォーマンスの課題についておこなった改善をご説明します。
リリース判定基準の策定
私が入社時点で当初予定されていたリリース日が差し迫っていました。しかし、クローズドテスト開始前の想定よりもパフォーマンス改善に対する課題が根深く、正式リリースの規模に耐えうるパフォーマンス改善の目処が立っていない状態でした。なので、まずはパフォーマンスについてどのような状態になっていればリリース可能かというリリース判定基準を定めました。リリース判定基準ではリリース時の想定RPS(Requests Per Second)を決め、それに対するSLO(Service Level Objective)とコストの目標値を設定しました。
SLO
SLOはレイテンシや可用性といった測定値に対して、外部からシステムに対して期待されるものとして設定された目標値です。
An SLO is a service level objective: a target value or range of values for a service level that is measured by an SLI.
SLOはレイテンシと可用性について一般的な目標値を設定しました。
・レイテンシ
CUJ(Critical User Journey)におけるAPIのレイテンシが、99th percentileで1秒以内
・可用性
CUJにおけるAPIの可用性が99%
CUJはユーザにとって重要な体験を指します。ホロプラスではCUJを以下のように定めました。
新規登録、ログイン
ホーム、コミュニティ、スレッド、コメント、いいねの表示
スレッドの投稿
コメントの投稿、返信
投稿へのいいね
料金
インフラの料金の目標は、シンプルな性能検証を行った際に必要な料金をもとに概算しました。ホロプラスではDBにAurora Serverless V2を使用していますが、その料金の目標は下記の記事を参考にさせていただきました。
記事の内容から10,000QPSさばくには少なくとも16ACUは必要なので、それにバッファをもたせて目標としました。
パフォーマンスチューニング
次に実際におこなったパフォーマンスチューニングをご説明します。
Datadogのモニタリングの内容からAurora Serverless V2のCPU使用率が100%に張り付いており、これがボトルネックであることはわかっていました。よって、Datadog APMやRDSのPerformance Insightsで高負荷のクエリを特定してひたすらインデックスを貼りました。また、以下のようなアプリケーションロジックの修正もおこないました。
N+1の撲滅
不要なクエリの削減
大きなテーブル間のJOINの削減
その過程で、使用していたORMのbunに修正を入れてそれが取り込まれました。
地道な修正ではありますがこれが功を奏し、APIのレイテンシは99th percentileで4秒から1.5秒程度まで下げることができました。
Provisionedへの移行の検討
レイテンシを1.5秒まで下げることはできましたが、まだ目標には届いていません。そこでアプリケーションの設計変更と同時にAurora Serverless V2からProvisionedへ移行し、コストパフォーマンスを上げることを検討しました。結論としては移行しませんでしたが検討内容をご説明します。
DBのコストパフォーマンスを上げたい旨をAWSのソリューションアーキテクトの方々に相談したところ、Aurora Serverless V2のライターをProvisionedに替えるご提案を頂きました。
Aurora Serverless V2からの移行方法は、Provisionedのリーダーを立て、Aurora Serverless V2のライターを強制フェイルオーバーさせます。これにより、Provisionedのリーダーがライターに昇格します。
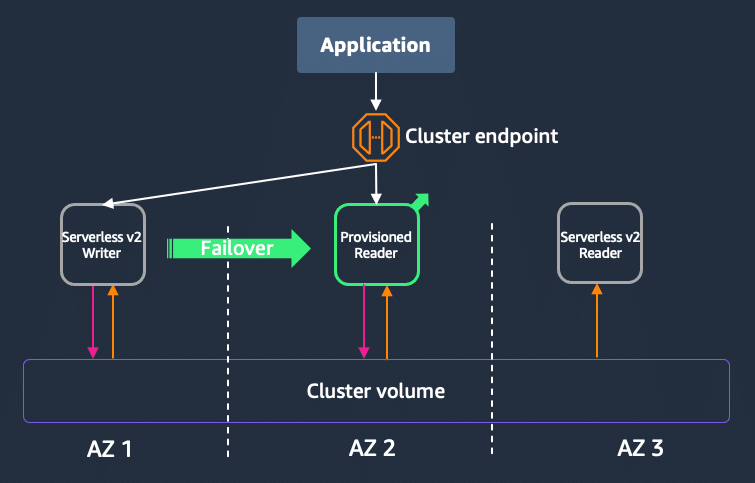
また、このServerlessとProvisionedのハイブリッド構成ですとライターが落ちた時のフェイルオーバーができないため、Aurora Multi-Masterでライターの可用性を高めることを検討する必要があります。
前述の通り、検討を進めていた過程でアプリケーションの設計変更がうまくいき、99th percentileが100〜200msに改善したため移行は保留しました。
アプリケーションの設計変更
Provisionedへの移行と並行して進めたアプリケーションの設計変更についてご説明します。
Performance Insightsを確認したところ以下のクエリがDBに大きな負荷をかけていました。クエリ内のテーブル名やカラム名は仮のものです。
SELECT posts.id, SUM(likes.total) AS like_count FROM posts LEFT JOIN
likes ON posts.id = likes.post_id GROUP BY posts.id LIMIT 10 ホロプラスの投稿一覧における投稿毎のいいね数を取得するものです。集計関数やGROUP BYによってDBに負荷がかかっているため、いいね数の集計を非同期処理に移しました。いいねを押すとSQSにイベントがキューイングされ、時間経過かイベント数がある程度たまったら、Lambdaでいいね数の総数を集計してDBに書き込まれるようになっています。

結果として、以下のクエリのように集計関数やGROUP BYを使う必要がなくなり、DBへの負荷が改善されました。
SELECT posts.id, posts.like_count FROM posts LIMIT 10 以上の改善でリリース判定基準のSLOを達成し、料金においても当初の1/3まで下げ、目標を達成することができました。
開発環境の改善
CI/CD
私がチームに入った当初はECSへのデプロイやCDKのデプロイが自動化されていませんでした。そんな中リリース日は迫っており他にもやるべきことは多くあったため、理想形は意識しつつもリッチなパイプラインはつくらず、とにかく使えるものを早くつくることを意識しました。
ECSへのデプロイのGitHub Actionsはこのようになっています。
name: Deploy
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
env:
IMAGE_TAG: ${{ github.sha }}
steps:
- name: checkout
uses: actions/checkout@v3
- name: configure aws credentials
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: ***
aws-region: ap-northeast-1
- name: login ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
- name: build and push
uses: docker/build-push-action@v4
with:
push: true
tags: |
${{ steps.login-ecr.outputs.registry }}/api:${{ env.IMAGE_TAG }}
${{ steps.login-ecr.outputs.registry }}/api:main
platforms: linux/amd64
cache-from: type=gha
cache-to: type=gha,mode=max
- name: Download task definition
run: |
aws ecs describe-task-definition --task-definition *** --query taskDefinition > task-definition.json
- name: Fill in the new image ID in the Amazon ECS task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@v1
with:
task-definition: task-definition.json
container-name: ***
image: ${{ steps.login-ecr.outputs.registry }}/api:${{ env.IMAGE_TAG }}
# workaround https://github.com/aws/aws-cli/issues/3568
- name: Output cli-input-json
id: task-def-migration
run: |
echo $(cat ${{ steps.task-def.outputs.task-definition }} | jq 'del(.taskDefinitionArn) | del(.revision) | del(.status) | del(.requiresAttributes) | del(.compatibilities) | del(.registeredAt) | del(.registeredBy)') > ${{ env.TASK_DEFINITION_PATH }}
echo "task-definition=${{ env.TASK_DEFINITION_PATH }}" >> $GITHUB_OUTPUT
env:
TASK_DEFINITION_PATH: ${{ runner.temp }}/task-definition-migration.json
- name: Run ECS task
uses: yyoshiki41/ecs-run-task-action@v0.0.8
with:
task-definition: ${{ steps.task-def-migration.outputs.task-definition }}
task-definition-family: ***
cluster: ***
subnets: ***
security-groups: ***
container-name: ***
command: '["/migration_cmd"]'
- name: Run ECS task
uses: yyoshiki41/ecs-run-task-action@v0.0.8
with:
task-definition: ${{ steps.task-def-migration.outputs.task-definition }}
task-definition-family: ***
cluster: ***
subnets: ***
security-groups: ***
container-name: ***
command: '["/seed_cmd"]'
- name: Deploy Amazon ECS task definition
uses: aws-actions/amazon-ecs-deploy-task-definition@v1
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: ***
cluster: ***
ECSへのデプロイはシンプルにTask DefinitionをデプロイしてRolling Updateしています。また、デプロイの前にDBのマイグレーションやマスタデータの投入をおこなう必要があります。そちらはまず最新のTask Definitionをダウンロードし、イメージのタグだけECRにプッシュしたタグで書き換え、そのTask Definitionでマイグレーションのコマンドを実行するTaskを起動しています。
Blue/Greenデプロイなどはできていませんが、短い実装時間でデプロイを自動化することができました。また、APIのリリース時に毎回メンテナンスを入れていたオペレーションもなくなりました。
監視
監視がほとんどなかったため以下の監視をDatadogで作成しました。
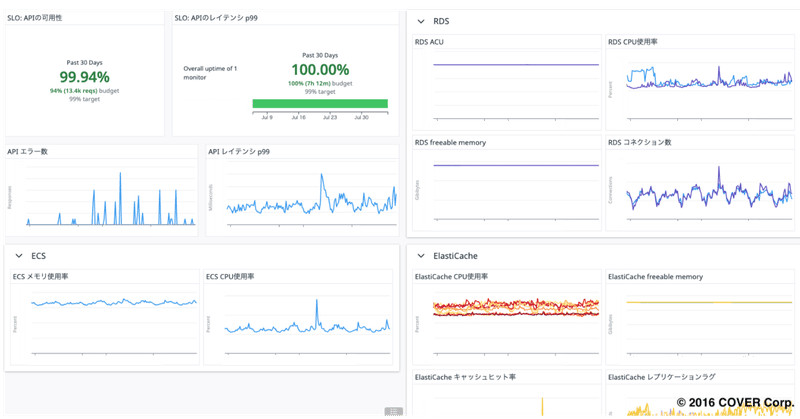
SLOのレイテンシ、可用性におけるエラーバジェット、バーンレートの監視
APIの外形監視
ALBでの死活監視、5xxエラー監視
ECSのCPU、メモリー監視
RDSのACU使用率、CPU、メモリー監視
ElastiCacheのCPU、メモリー、キャッシュヒット率、レプリケーションラグ監視
また異常に至る傾向を確認できるように主要なメトリクスを集めたダッシュボードを作成しました。

その他の改善
その他にもGoのソフトウェアテストが動いていなかったため、CIでテストを動かすようにしてテストを書く習慣を取り戻しました。
また、扱いやすい分散負荷試験環境がなかったため、Distributed Load Testing on AWSを使うことにしました。JMeterの学習コストはありますがDistributed Load Testing on AWSは扱いやすく負荷試験を回す速度は向上しました。
まとめ
今回はホロプラスにおけるパフォーマンスチューニングや開発環境の整備についてご説明しました。パフォーマンスや開発環境の改善に興味のある皆さまの参考になれば幸いです。
こちらの改善内容について原因究明から設計、対策の主導をおこないましたが、実装などはチームの方々に多くのサポートをいただきました。また、AWSの方々にもオフィスアワーなどでご支援をいただきました。
この場をかりて感謝を申し上げます。
最後までご覧いただきありがとうございました。カバー株式会社ではエンジニアを積極採用しております。こちらの記事を読んで気になっていただけましたら、以下リンクよりご応募をお願いいたします。
