
AIこより爆誕!?の裏側

こんこよ~🧪
カバー株式会社CTO室エンジニアのAです。
カバー株式会社には2023年4月に新卒で入社し、第1回COVER Techを執筆したKさんの下で、タレントの皆様が日々のYouTube配信などで使用するホロライブアプリの開発に携わっています。
また、ここ数か月はそれと並行してAIこよりシステムの開発を担当してまいりました。
この記事では開発したシステムの概要についてご紹介します。
開発経緯
AIこよりシステムの開発に至った経緯について。
まず社内に生成AIの可能性や関連技術の検討をしたいという需要がありました。そこへ、こよりさんからご自身のAIを作りたいというご要望をいただいたため、それがきっかけとなり、こよりさんの全面的なご協力の下でAIこよりシステムの開発が始まりました。
システム概要
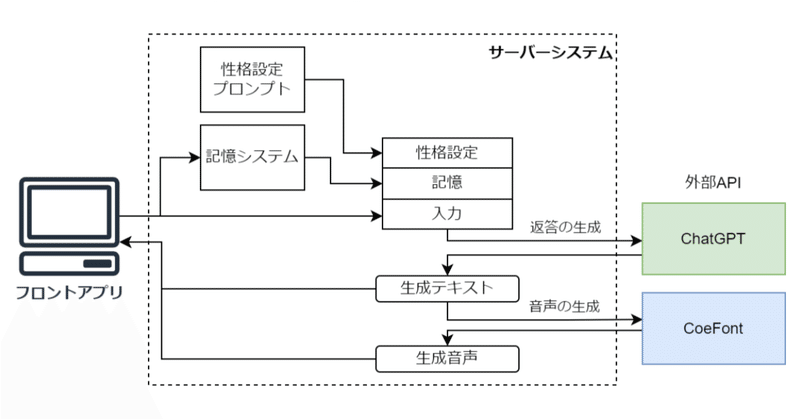
今回開発したものは、AIシステムへの入出力を操作し配信画面に映すフロントアプリと、各種外部APIとのやりとりや内部データの処理をするサーバーシステムに分けられます。
システムの全体は下図のようになっています。

フロントアプリ
フロントアプリには大きく分けて 1. 入力 2. 返答のチェック 3. 返答の表示 の3つの処理フローがあります。

入力
現在フロントアプリはテキスト入力と音声入力に対応しています。音声入力時の音声の文字起こしにはOpenAI APIのWhisperを利用しています。返答のチェック
入力に対するAIの返答が返ってきたら、その内容をチェックします。今回利用しているChatGPTは非倫理的な発言をしないように調整されていますが[1][2]、絶対に安心というわけではなく、配信に乗せるには不適切な内容が含まれる可能性もあります。これに対して、フロントアプリ上でAIの返答内容の確認画面と、実際に配信に映す画面を分けて作り、一度内容を確認したうえで配信に表示するという(Human in the loop [3]の)フローを構築しています。返答の表示
AIの読み上げ音声の再生やテキスト表示アニメーションをコントロールします。
その他にも、こよりさんの配信企画のニーズに応じて各種機能を実装しております。
サーバーシステム
サーバーシステムでは 返答テキストの生成 ・返答読み上げ音声の生成 を行っています。
返答テキストの生成
AIの返答の生成にはChatGPT(gpt-3.5-turbo)を利用しています。
ChatGPTへの入力は ■性格設定 ■会話の記憶 ■現在の入力 で構成されます。
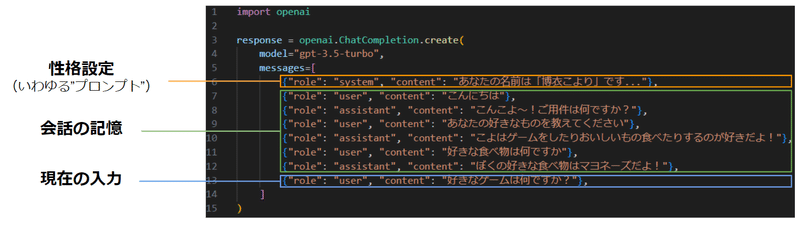
■性格設定
性格設定のプロンプトはこよりさんご自身による監修の元作成しました。ChatGPTのキャラクター化や性格設定の知見については紹介している記事が他にもたくさんあるため、基本的な部分は本記事では割愛します。1点、口調の切り替わり挙動の実装についてご説明します。
こよりさんからのご要望で、口調を丁寧語とため口で切り替えたいというものがありました。入力から「ため口で話して」「敬語を使って」等と指示することで、口調が切り替わるという挙動です。
これに対して、まずは、
・プロンプトによる指示
・例文の提示
による挙動の設定を試みました。以下に示すプロンプト例は実際に使用しているものとは異なります。
character = 博衣こより
{Character}'s tone: {
You speak in either a casual or honorific tone.
You switch your tone if you are requested.
Examples of honorific tone:
...
Examples of casual tone:
...
}
Examples of dialogue: {
Example of dialogue 1:
User: こんにちは
Character: こんこよ~!ご用件は何ですか?
User: ため口で話してください
Character: わかった!こんな感じで話すね!
Example of dialogue 2:
...
}
しかし、この方法だけでは口調が安定しなかったり、指示通りに口調が切り替わらないという挙動が見られました。
これを受けて、さらに出力の口調に対してラベルを付けるように指示を追加しました。出力を辞書型とし、返答の口調(tone)がため口の場合は”casual”、敬語の場合は”honorific”とラベル付けするように指示しました。
character = 博衣こより
{Character}'s tone: {
You can take tone value as "honorific" or "casual".
Your default tone is "honorific".
You switch your tone if you are requested.
You must indicate your current tone, "honorific" or "casual", in your output.
Examples of "honorific":
...
Examples of "casual":
...
}
Examples of dialogue: {
You must output your reply and your current tone in dictionary format, like {"reply": "Your reply here", "tone": "honorific" or "casual"}.
Example of dialogue 1:
User: こんにちは
Character: {"reply": "こんこよ~!ご用件は何ですか?", "tone": "honorific"}
User: ため口で話してください
Character: {"reply": "わかった!こんな感じで話すね!", "tone": "casual"}
Example of dialogue 2:
...
}
結果、gpt-4においては安定して口調を切り替えることができ、gpt-3.5でもある程度安定して挙動することを確認できました。
■会話の記憶
簡単に実装するのであれば、直近n件の入出力を保持する方法が考えられますが、この方法ではそれ以前の会話の情報が失われてしまいます。これに対して、本システムではこちらの論文[4]を参考に記憶システムを構築しました。
今回実装した記憶システムは、すべての記憶(過去の会話)から関連度の高い記憶のみを抽出してChatGPTへの入力に含めるという方式を取っています。
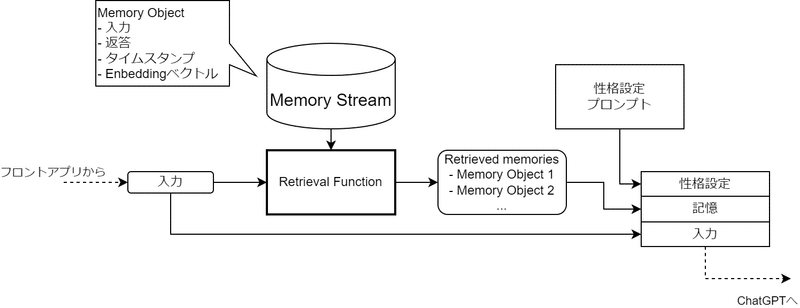
Memory Stream: 保存されているすべてのMemory Object
Retrieval Functionにより、入力と、Memory Streamのそれぞれの記憶とのRetrieval Scoreを算出し、スコア上位n件の記憶をRetrieved memoriesとしてChatGPTへの入力プロンプトに含めています。
$${i}$$番目の記憶のRetrieval Scoreは下式で算出され、入力とMemory Stream内のそれぞれの記憶との関連度合いを表しています。
$${RetrievalScore = w_1 Recency + w_2 Relevance}$$
$${Recency = e^{- \alpha (t_I - t_{M_i})}}$$
$${Relevance = \frac{E_{I} \cdot E_{M_i}}{||E_{I}|| ||E_{M_i}||}}$$
ここで、$${w_1}$$、$${w_2}$$は重み付け係数、$${t_I}$$は入力の時刻、$${t_{M_i}}$$は$${i}$$番目の記憶の時刻、$${E_I}$$は入力のEmbeddingベクトル、$${E_{M_i}}$$は$${i}$$番目の記憶のEmbeddingベクトル、$${(\cdot)}$$はドット積です。
また、今回は$${\alpha = 2.0 \times 10^{-4}}$$(1時間でおよそ半減)としています。
Embeddingベクトルとは、文章を1,536次元の数値ベクトルに変換したもので、文章の特徴を表現しています。ベクトル間の距離は文章同士の関連度合いを表します[5]
本システムではOpenAI APIのEmbeddingsを使用して、入力と返答を繋ぎ合わせた文章のEmbeddingベクトルを取得し、これをMemory ObjectのEmbeddingベクトルとしています。
上式は以下のことを表現しています。
Recency
入力を受け取った時刻とそれぞれのMemory objectの時刻の差分に応じて指数関数で減衰する値。
直近のMemoryほどRecencyの値が大きくなります。
Relevance
入力のEmbeddingとそれぞれのMemoryのEmbeddingのコサイン類似度。
この値は、入力とそれぞれのMemoryの類似度を示し、類似度が高いものほどRelevanceの値が大きくなります。
システム稼働当初は、このアルゴリズムによりretriveされた20件のMemory objectをChatGPTへの入力プロンプトに含めていました。しかし実際にやりとりをする中で話題が前後するなどの予期しない挙動が見られたため、現在では、
・直近10件のMemory objectを入力プロンプトに含める
・それ以前のMemory objectからRetrieval scoreの上位10件のものをプロンプトに含める
というアルゴリズムになっています。
返答読み上げ音声の生成
読み上げAIモデルの学習および利用はCoeFontさんのサービスを利用しています。
CoeFontを採用した理由として、
・APIからの利用が可能
・学習データの収録がブラウザ上で可能
という点があります。
特に学習データの収録が手軽という点が大きく、タレントさんの稼働を圧迫せず、ご自宅から空いた時間に収録を行っていただくことができました。今回は学習データとして3,000文の文章をこよりさんに収録していただきました(大変なお仕事をありがとうございました…!)。
本システムでは、CoeFontの提供するAPIに読み上げるテキストを送り、生成された音声データをフロントアプリで再生しています。
まとめ
今回はAIこよりシステムの全体的な概要についてご紹介しました。今回私が作成したのは、既存のサービスや技術を繋ぎ合わせたごく簡単なシステムでしかありません。これを活用し、楽しいコンテンツに昇華させるのは、こよりさんをはじめとするタレントの皆様のアイデアとクリエイティビティです。私たちは今後もタレントの皆様のアイデアを技術でサポートし、また常に新しい技術にリーチし続けることで、ファンの皆様に楽しんでいただくことを目標に開発に取り組みます。
参考文献
[1] OpenAI Documentation, “Model index for researchers”, OpenAI,
[2] O. Long et. al., “Training language models to follow instructions with human feedback”, arXiv, 2023
[3] OpenAI Documentation, “Safety best practices”, OpenAI,
[4] J. S. Park et. al., “Generative Agents: Interactive Simulacra of Human Behavior”, arXiv, 2023
[5] OpenAI Documentation, “What are embeddings?”, OpenAI,