

カバーで行っているAIの取り組みを紹介

こんまっする~!⚔️
カバー株式会社CTO室のIです。カバー株式会社では組織横断的にSREやCCoEのエンジニアをしています。
カバー株式会社のCTO室のミッションの一つに、プロダクト開発チームの代わりに新しい技術の導入や検証を行いそれを組織全体へ還元することがあります。
今回は、社内で検証を行っているLLM/Generative AIを開発へ活用する取り組みの一部をご紹介します。
まず、社内でAI活用に関してヒアリングを行ったところ需要が大きかったユースケースが下記の2つでした。
コード生成
仕様書やコードをデータソースにした仕様の返答が可能なチャットボット
コード生成に関しては既に、GitHub Copilot for Businessの導入が進んでいたため検証ではチャットボットサービスを探すこととなりました。
チャットボットといえば名前の上がるのがChatGPTですが、ChatGPTは学習を行ったタイミングまでのデータしか学習していません。そのため、社内ドキュメントに関する質問を行っても、『質問内容が分からない』という回答や、意図とは異なる回答が返ってくることになります。
社内ドキュメントを認識させる場合はRetrieval Augmented Generation(以下、RAG)という概念を利用してチャットボットを拡張する必要があります。
ChatGPTには標準機能としてRAGに相当する機能がないため、ChatGPTと同じGPT-4を利用できる尚且つRAGに相当する機能のあるAzure OpenAI Serviceを利用してチャットボットを構築することとしました。
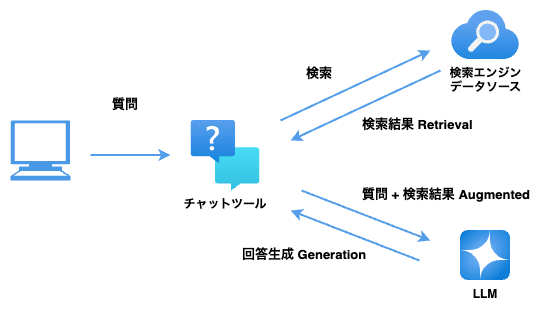
RAGの仕組み
Retrieval Augmented Generationとある通り、RAGの基本的な仕組みは、ユーザが質問を行った際にそれに関連するドキュメントなどを検索し、その結果を質問と一緒にLLMへ渡すことで正確な回答生成するという流れになっています。
チャットボットを構築
今回はGitHub Azure Samplesにあるazure-search-openai-demoを利用してAzure AI Searchで検索を行うチャットボットをAzureに構築してPDFについての質問に回答できるかを確認してみます。
https://github.com/Azure-Samples/azure-search-openai-demo/tree/main
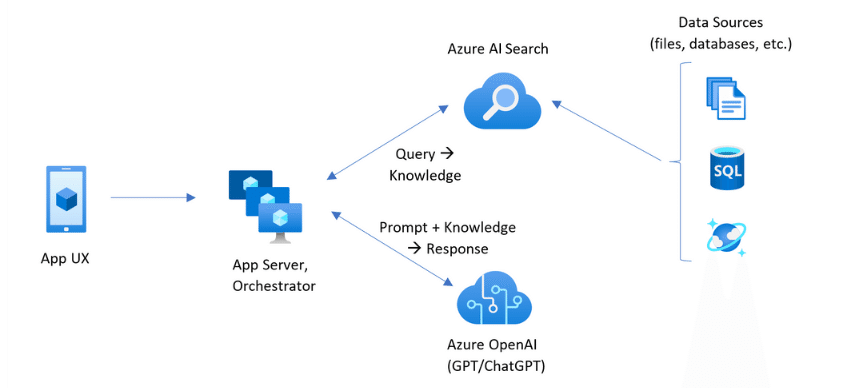
Azure OpenAI Serviceアーキテクチャ
https://learn.microsoft.com/ja-jp/azure/search/retrieval-augmented-generation-overview
ローカルにテンプレートを展開
$ azd init -t azure-search-openai-demo低コストで展開する設定を追加
https://github.com/Azure-Samples/azure-search-openai-demo/blob/main/docs/deploy_lowcost.md
$ azd env set AZURE_APP_SERVICE_SKU F1
$ azd env set AZURE_SEARCH_SERVICE_SKU free
$ azd env set AZURE_DOCUMENTINTELLIGENCE_SKU F0
$ azd env set AZURE_USE_APPLICATION_INSIGHTS falseAzureへデプロイ
$ azd up
Packaging services (azd package)
(✓) Done: Packaging service backend
- Package Output: /tmp/azure-search-openai-demo-backend-azddeploy-1710824424.zip
SUCCESS: Your application was packaged for Azure in 10 seconds.
Checking if authentication should be setup...
Loading azd .env file from current environment...
AZURE_USE_AUTHENTICATION is not set, skipping authentication setup.
Provisioning Azure resources (azd provision)
Provisioning Azure resources can take some time.
Subscription: cover-ai-test
Location: East US 2
You can view detailed progress in the Azure Portal:
https://portal.azure.com/#view/HubsExtension/DeploymentDetailsBlade/~/overview/id/%2Fsubscriptions%2F4b8c2dc4-30ac-484f-9e2a-f482cd719ac5%2Fproviders%2FMicrosoft.Resources%2Fdeployments%2Fazure-openai-rag-dev-1710824426
(✓) Done: Resource group: rg-azure-openai-rag-dev
(✓) Done: Search service: gptkb-hxmdepso4jfjg
(✓) Done: Azure OpenAI: cog-hxmdepso4jfjg
(✓) Done: Storage account: sthxmdepso4jfjg
(✓) Done: Key Vault: kv-hxmdepso4jfjg
(✓) Done: Document Intelligence: cog-di-hxmdepso4jfjg
(✓) Done: App Service plan: plan-hxmdepso4jfjg
SUCCESS: Your application was provisioned in Azure in 4 minutes 59 seconds.
You can view the resources created under the resource group rg-azure-openai-rag-dev in Azure Portal:
https://portal.azure.com/#@/resource/subscriptions/xxxxxxx/resourceGroups/rg-azure-openai-rag-dev/overview
Deploying services (azd deploy)
(✓) Done: Deploying service backend
- Endpoint: https://app-backend-asjfasiufhasfui.azurewebsites.net/
SUCCESS: Your application was deployed to Azure in 3 minutes 22 seconds.
You can view the resources created under the resource group rg-azure-openai-rag-dev in Azure Portal:
https://portal.azure.com/#@/resource/subscriptions/xxxxxxx/resourceGroups/rg-azure-openai-rag-dev/overview
SUCCESS: Your up workflow to provision and deploy to Azure completed in 14 minutes 12 seconds.
rg-azure-openai-rag-dev in Azure PortalのURLにアクセス
無事にチャットボットへアクセスできました。

今回はサンプルとしてデジタル庁が提供している「デジタル社会推進実践ガイドブックDS-120 デジタル・ガバメント推進標準ガイドライン実践ガイドブック」の1章を社内ドキュメントとして利用します。
まず、Notionへ取り込みを行いそのページをPDFとしてAzure AI Searchに取り込んでみます。
https://www.digital.go.jp/resources/standard_guidelines
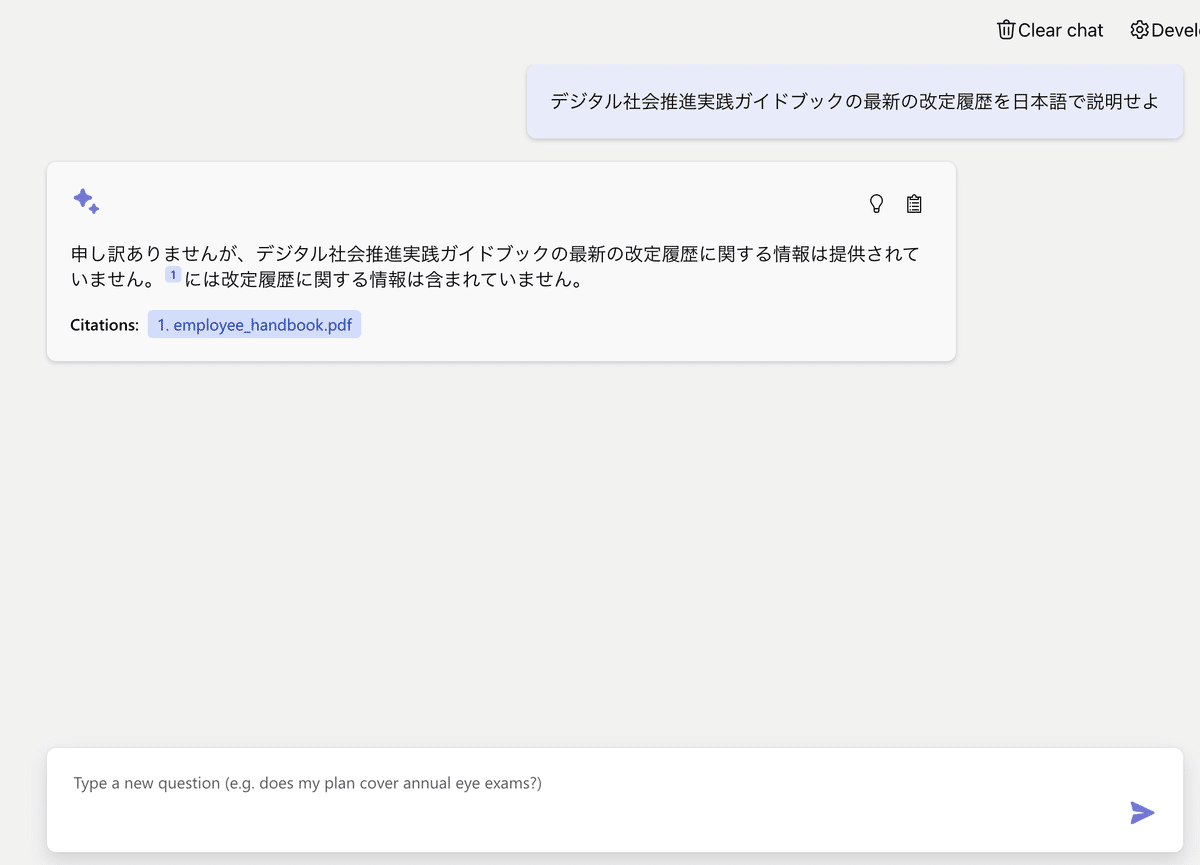
まず、先ほど構築した初期状態のチャットボットに対して、上記のデジタル庁のドキュメントに関する質問をしてみます。
質問内容は、1章のドキュメントにある改定履歴について聞いてみます。
結果は、GPTからデジタル社会推進実践ガイドブックに関する情報がないと返答が返ってきました。
質問結果
読み込ませる内容

PDFをAzure AI Searchに取り込んでみます。
テンプレートディレクトリ内にある「./data」内に「guidebook01.pdf」という名前でPDFを配置して再度デプロイします。
$ azd up
Using local files: ./data/*
Ensuring search index gptkbindex exists
Search index gptkbindex already exists
Skipping ./data/GPT4V_Examples/Financial Market Analysis Report 2023.pdf, no changes detected.
Skipping ./data/Northwind_Standard_Benefits_Details.pdf, no changes detected.
Ingesting 'guidebook01.pdf'
Extracting text from './data/guidebook01.pdf' using Azure Document Intelligence
Splitting 'guidebook01.pdf' into sections
Section ends with unclosed table, starting next section with the table at page 0 offset 0 table start 710
Uploading blob for whole file -> guidebook01.pdf
Computed embeddings in batch. Batch size: 8, Token count: 2748
Skipping ./data/PerksPlus.pdf, no changes detected.
Skipping ./data/Northwind_Health_Plus_Benefits_Details.pdf, no changes detected.
Skipping ./data/role_library.pdf, no changes detected.
Skipping ./data/Benefit_Options.pdf, no changes detected.
Skipping ./data/employee_handbook.pdf, no changes detected.
Skipping ./data/Json_Examples/2192.json, no changes detected.
Skipping ./data/Json_Examples/2189.json, no changes detected.
Skipping ./data/Json_Examples/query.json, no changes detected.
Skipping ./data/Json_Examples/2190.json, no changes detected.
Skipping ./data/Json_Examples/2191.json, no changes detected.
Skipping ./data/Contoso_Electronics_Company_Overview.md, no changes detected.
SUCCESS: There are no changes to provision for your application.デプロイが終わったので、先ほどと同じ質問を行います。
結果は、Azure AI Searchに追加したPDF内容を読み込んで回答されている事が確認できました。

実運用を想定した際に解決するべき課題
定期的にAzure AI Searchのデータを更新する
実運用を想定すると、Azure AI Search内にある社内ドキュメントデータを定期的に更新する必要が出てきます。
解決策として、2月にリリースされたAzure OpenAI On Your Dataを利用する事で、定期的にAzure Blob Storageに配置したファイルを読み取りAzure AI Searchのデータを最新ドキュメントにする事が可能となります。
https://learn.microsoft.com/ja-jp/azure/ai-services/openai/concepts/use-your-data?tabs=blob-storage
ユーザ単位でアクセス出来るドキュメントを制限する
社内ドキュメントには企画中のコンテンツ情報などが存在しており、そういった情報は社内でも限られた人しかアクセス出来ない状態となっています。
ですが、Azure AI Searchは取り込んだドキュメントやインデックス構造へのアクセス制御機能を提供していません。
ですので、社内ドキュメントと同じアクセス制御をチャットボットでも実現するためには、Azure AI Searchのデータにアクセス制御に利用するグループやユーザ情報をフィールドとして追加を行い、チャットボット側からの検索時に検索内容と一緒にグループやユーザ情報を付与して検索を行うことになります。
https://learn.microsoft.com/ja-jp/azure/search/search-security-trimming-for-azure-search
まとめ
社内ドキュメントをAzure AI Searchを利用してGPTが認識することが可能なのも確認しました。
ドキュメントのアクセス制御に関しては課題はありますが広く利用されるドキュメントのみであれば十分利用が可能なことがわかりました。
LLM系のプロダクトはアップデートが早く、弊社でも現在はAzure AI Studio(プレビュー)のプラグインを利用したHTTP経由でのドキュメントアクセスを行う手法を模索しています。
そちらも検証が終わりましたらご紹介したいと思います。